

The exchange and processing of large data volumes from diverse sources are commonplace in modern enterprise projects. Additionally, the shift towards microservices architectures necessitates robust data exchange mechanisms. Message brokers, serving as intermediaries, facilitate this by managing communications between different applications, services, and systems. This article examines whether message brokers are always necessary, and if so, which of the popular options—RabbitMQ or Apache Kafka—best suits various scenarios.
A message broker is a software system designed to handle the transmission of messages between producers and consumers without direct interaction between them. Producers send messages to the message broker, which then routes these to the appropriate consumers. This setup decouples producers from consumers, allowing for independent operation, scalability, and evolution without direct impact on each other. Message brokers are essential for managing asynchronous communications in distributed systems, offering reliable message delivery, scalability, and the capacity to handle high message volumes and complex workflows.
Implementing a message broker is ideal when asynchronous communication and reliable data delivery are critical. They shine in environments where systems or components must exchange data reliably without being connected directly, such as in distributed architectures with loosely coupled components. However, for requirements prioritizing speed and immediate data access—where durability and asynchronous communication are less critical—alternatives like direct API calls or caching mechanisms may be more appropriate. In scenarios demanding real-time data processing and immediate state reflection, direct integration services or in-memory data stores could better serve performance needs.
Currently, the most popular brokers are RabbitMQ and Apache Kafka. Although they serve similar functions globally, they are fundamentally different in their data storage structures, reading approaches, and application scenarios.
RabbitMQ: Versatile and Reliable
RabbitMQ, a widely adopted message broker, excels in versatility and robustness, built on the Erlang OTP platform known for reliable distributed system management. It employs exchanges to route messages to queues based on defined rules, supporting various exchange types like direct, topic, and fanout.
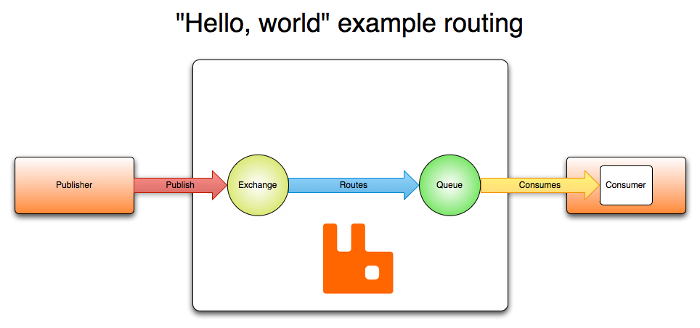
In this system, consumers can subscribe to specific messages or to topics through topic exchanges. The subscription model is flexible, allowing for both exact and pattern-based matching to control message delivery. Consumers must acknowledge the receipt and processing of each message. This mechanism ensures that messages are safely removed from the queue only after they are properly handled. If a message is not acknowledged, it can be redelivered to the same consumer or another consumer, depending on the configuration. If a consumer fails to process a message and does not acknowledge it, RabbitMQ can requeue the message. This can be configured to happen automatically or manually. Additionally, messages can be marked with a “dead letter” flag and moved to a dead letter exchange if they fail to be processed after a certain number of attempts, providing a way to handle message processing failures more gracefully.
The management of queues is crucial in RabbitMQ to prevent resource exhaustion, which could lead to performance degradation or crashes. It’s important to monitor queue lengths and use features like TTL (time-to-live), queue length limits, and dead-letter exchanges to manage queue buildup effectively.
RabbitMQ provides various features to enhance performance and reliability, including durable queues, persistent messages, and high availability options. Clustering and mirrored queues help in providing redundancy and failover capabilities.
Last but not least – this message broker supports a wide variety of plugins that extend its capabilities, and it has client libraries for multiple programming languages including Java, C#, Node.js, Python, Ruby, and others, making it highly versatile. It has excellent support for legacy messaging protocols such as STOMP and MQTT, which makes it highly compatible with older systems and diverse application requirements.
Apache Kafka: Built for High Throughput
Designed for high-load environments, Apache Kafka handles vast data volumes efficiently, making it suitable for processing terabytes to petabytes of data. Kafka’s simple broker design, which minimizes its responsibility over consumer message tracking, shifts complexity to consumers who manage their message offsets.
Kafka operates on a “Dumb Messenger / Smart Consumer” principle where the broker (messenger) has no “smart” features for storage or routing, and maintains minimal state about message consumption. It retains messages for a configurable period, known as the retention time, irrespective of whether messages have been consumed. This model offloads complexity to the consumer, which is responsible for keeping track of what has been read (offset management), handling message processing logic, and implementing features like dead letter queues if needed.
The storage model here is built around Topics and Partitions. Topics are like logs, where messages are appended in an immutable sequence. Topics are divided into partitions to allow the dataset to be scaled across multiple nodes, facilitating parallel processing. Each partition is an ordered, immutable sequence of records that is continually appended to—a structured commit log. Kafka guarantees order within a partition but not across multiple partitions by default. This partitioning mechanism enhances data throughput and scalability.
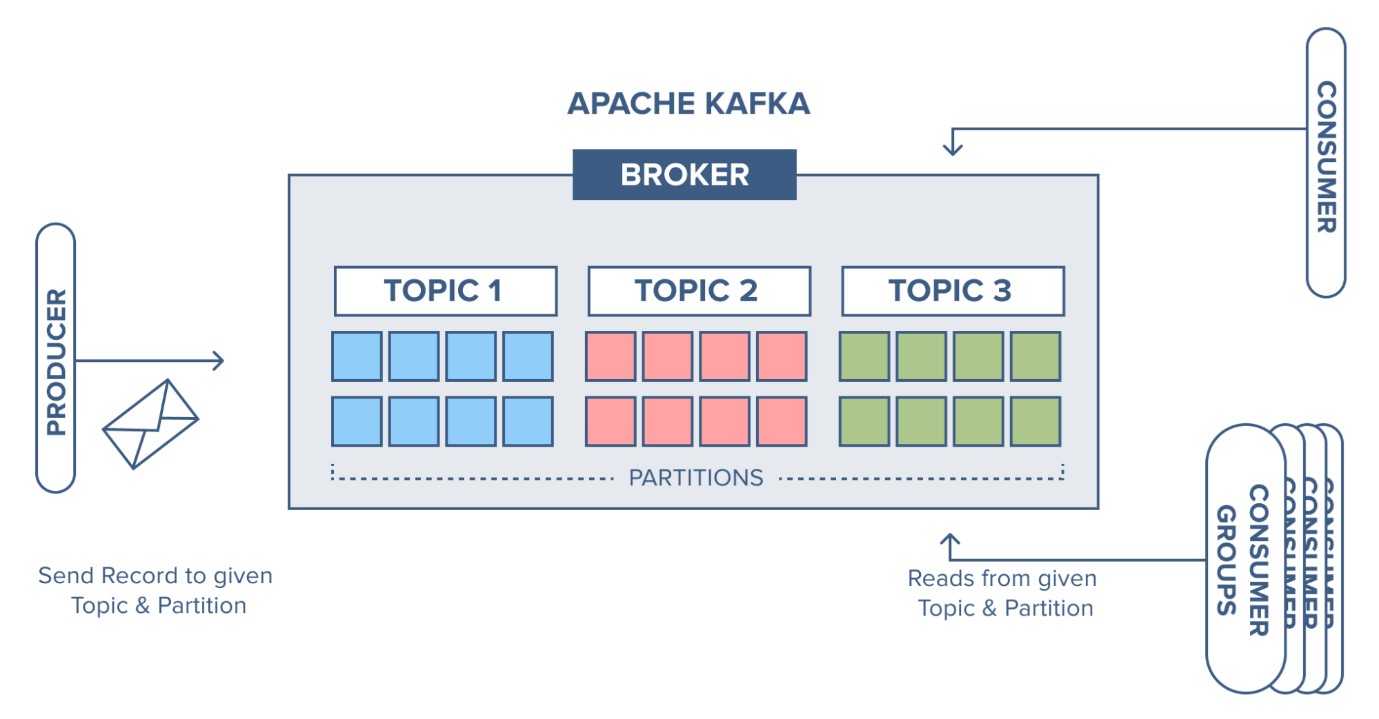
Unlike many traditional messaging systems where the server pushes data to consumers, Kafka employs a pull model where the consumer requests new data. This approach allows consumers more control over message consumption pace and can lead to more efficient processing by adapting to the consumer’s capacity.
Kafka is not only a messaging system but also a powerful stream processing platform. It supports complex processing pipelines and real-time data processing applications through Kafka Streams and KSQL. Kafka Streams API allows for building robust data processing applications that are scalable, elastic, and fully integrated with Kafka. It enables applications to process data in real-time directly from Kafka topics.
Apache Kafka supports the concept of consumer groups to allow a group of processes to cooperatively consume data from the same topic. Each consumer in the group reads from a unique partition, enhancing parallelism and fault tolerance.
Choosing Between the Two
The choice between RabbitMQ and Apache Kafka depends largely on specific project requirements. RabbitMQ is preferable for scenarios requiring a wide range of messaging features and easy integration with various protocols and systems, particularly where complex routing capabilities are needed. Conversely, Kafka is better suited for projects demanding high throughput and scalable, durable message storage, particularly in systems where stream processing and real-time data handling are priorities.